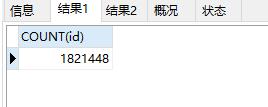
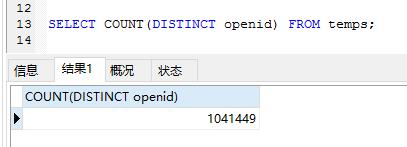
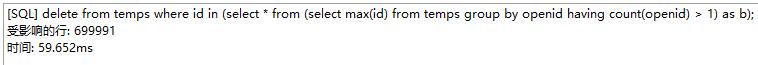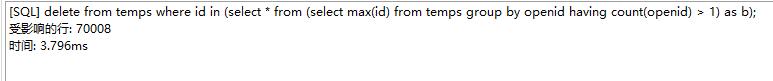表的范式、是首先符合1NF 才能符合2NF 进一步满足 3NF
第一范式:1NF是对属性的原子性约束,要求属性(列)具有原子性,不可再分解 (只要是关系型数据库 自动满足第一范式)
第二范式:2NF是对记录的唯一性约束,要求每条记录既有唯一性 即实体的唯一性 (通常使用主键来完成,主键ID一般不包含业务逻辑,正因为不包含业务逻辑所以数据稳定)
第三范式:3NF是对字段的冗余性约束,要求字段完全没有冗余。(一个字段的内容重复出现多次或者可以在另一张表中可以推算出来的数据 即为冗余数据)
反范式化
反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能。
备注:但是有些情况下 完全符合3NF的数据库也未必是好的数据库,有时候为了提高效率,可以适当的冗余数据,降低3NF标准,具体做法是:
在表的 1对N 情况下 可能会在1的那边设置一个 在为了提高效率 会在1那边设置一个反三范式的字段提速