什么是CGI
CGI 目前由NCSA维护,NCSA定义CGI如下:
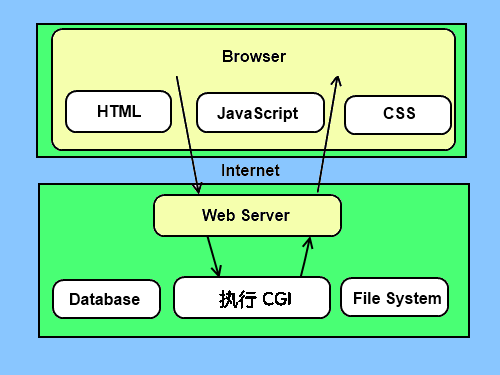
CGI(Common Gateway Interface),通用网关接口,它是一段程序,运行在服务器上如:HTTP服务器,提供同客户端HTML页面的接口。
网页浏览
为了更好的了解CGI是如何工作的,我们可以从在网页上点击一个链接或URL的流程:
- 1、使用你的浏览器访问URL并连接到HTTP web 服务器。
- 2、Web服务器接收到请求信息后会解析URL,并查找访问的文件在服务器上是否存在,如果存在返回文件的内容,否则返回错误信息。
- 3、浏览器从服务器上接收信息,并显示接收的文件或者错误信息。
CGI程序可以是Python脚本,PERL脚本,SHELL脚本,C或者C++程序等。
Web服务器支持及配置
在你进行CGI编程前,确保您的Web服务器支持CGI及已经配置了CGI的处理程序。
Apache 支持CGI 配置:
设置好CGI目录:
ScriptAlias /cgi-bin/ /var/www/cgi-bin/
所有的HTTP服务器执行CGI程序都保存在一个预先配置的目录。这个目录被称为CGI目录,并按照惯例,它被命名为/var/www/cgi-bin目录。
CGI文件的扩展名为.cgi,python也可以使用.py扩展名。
默认情况下,Linux服务器配置运行的cgi-bin目录中为/var/www。
如果你想指定其他运行CGI脚本的目录,可以修改httpd.conf配置文件,如下所示:
<Directory "/var/www/cgi-bin"> AllowOverride None Options +ExecCGI Order allow,deny Allow from all </Directory>
在 AddHandler 中添加 .py 后缀,这样我们就可以访问 .py 结尾的 python 脚本文件:
AddHandler cgi-script .cgi .pl .py
第一个CGI程序
我们使用Python创建第一个CGI程序,文件名为hello.py,文件位于/var/www/cgi-bin目录中,内容如下:
#!/usr/bin/python # -*- coding: UTF-8 -*- print "Content-type:text/html" print # 空行,告诉服务器结束头部 print '<html>' print '<head>' print '<meta charset="utf-8">' print '<title>Hello Word - 我的第一个 CGI 程序!</title>' print '</head>' print '<body>' print '<h2>Hello Word! 我是来自菜鸟教程的第一CGI程序</h2>' print '</body>' print '</html>'
文件保存后修改 hello.py,修改文件权限为 755:
chmod 755 hello.py
以上程序在浏览器访问显示结果如下:
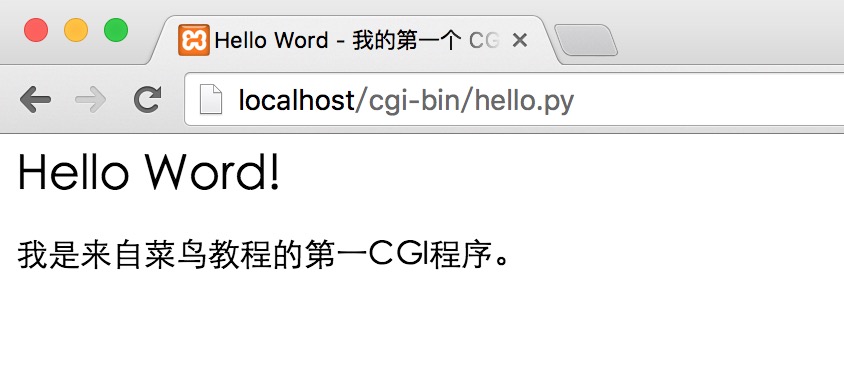
这个的hello.py脚本是一个简单的Python脚本,脚本第一行的输出内容”Content-type:text/html”发送到浏览器并告知浏览器显示的内容类型为”text/html”。
用 print 输出一个空行用于告诉服务器结束头部信息。
HTTP头部
hello.py文件内容中的” Content-type:text/html”即为HTTP头部的一部分,它会发送给浏览器告诉浏览器文件的内容类型。
HTTP头部的格式如下:
HTTP 字段名: 字段内容
例如:
Content-type: text/html
以下表格介绍了CGI程序中HTTP头部经常使用的信息:
| 头 | 描述 |
|---|---|
| Content-type: | 请求的与实体对应的MIME信息。例如: Content-type:text/html |
| Expires: Date | 响应过期的日期和时间 |
| Location: URL | 用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 |
| Last-modified: Date | 请求资源的最后修改时间 |
| Content-length: N | 请求的内容长度 |
| Set-Cookie: String | 设置Http Cookie |
CGI环境变量
所有的CGI程序都接收以下的环境变量,这些变量在CGI程序中发挥了重要的作用:
| 变量名 | 描述 |
|---|---|
| CONTENT_TYPE | 这个环境变量的值指示所传递来的信息的MIME类型。目前,环境变量CONTENT_TYPE一般都是:application/x-www-form-urlencoded,他表示数据来自于HTML表单。 |
| CONTENT_LENGTH | 如果服务器与CGI程序信息的传递方式是POST,这个环境变量即使从标准输入STDIN中可以读到的有效数据的字节数。这个环境变量在读取所输入的数据时必须使用。 |
| HTTP_COOKIE | 客户机内的 COOKIE 内容。 |
| HTTP_USER_AGENT | 提供包含了版本数或其他专有数据的客户浏览器信息。 |
| PATH_INFO | 这个环境变量的值表示紧接在CGI程序名之后的其他路径信息。它常常作为CGI程序的参数出现。 |
| QUERY_STRING | 如果服务器与CGI程序信息的传递方式是GET,这个环境变量的值即使所传递的信息。这个信息经跟在CGI程序名的后面,两者中间用一个问号’?’分隔。 |
| REMOTE_ADDR | 这个环境变量的值是发送请求的客户机的IP地址,例如上面的192.168.1.67。这个值总是存在的。而且它是Web客户机需要提供给Web服务器的唯一标识,可以在CGI程序中用它来区分不同的Web客户机。 |
| REMOTE_HOST | 这个环境变量的值包含发送CGI请求的客户机的主机名。如果不支持你想查询,则无需定义此环境变量。 |
| REQUEST_METHOD | 提供脚本被调用的方法。对于使用 HTTP/1.0 协议的脚本,仅 GET 和 POST 有意义。 |
| SCRIPT_FILENAME | CGI脚本的完整路径 |
| SCRIPT_NAME | CGI脚本的的名称 |
| SERVER_NAME | 这是你的 WEB 服务器的主机名、别名或IP地址。 |
| SERVER_SOFTWARE | 这个环境变量的值包含了调用CGI程序的HTTP服务器的名称和版本号。例如,上面的值为Apache/2.2.14(Unix) |
以下是一个简单的CGI脚本输出CGI的环境变量:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# filename:test.py
import os
print "Content-type: text/html"
print
print "<meta charset=\"utf-8\">"
print "<b>环境变量</b><br>";
print "<ul>"
for key in os.environ.keys():
print "<li><span style='color:green'>%30s </span> : %s </li>" % (key,os.environ[key])
print "</ul>"
将以上点保存为 test.py ,并修改文件权限为 755,执行结果如下:
GET和POST方法
浏览器客户端通过两种方法向服务器传递信息,这两种方法就是 GET 方法和 POST 方法。
使用GET方法传输数据
GET方法发送编码后的用户信息到服务端,数据信息包含在请求页面的URL上,以”?”号分割, 如下所示:
http://www.test.com/cgi-bin/hello.py?key1=value1&key2=value2
有关 GET 请求的其他一些注释:
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
简单的url实例:GET方法
以下是一个简单的URL,使用GET方法向hello_get.py程序发送两个参数:
/cgi-bin/test.py?name=菜鸟教程&url=http://www.runoob.com
以下为hello_get.py文件的代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# filename:test.py
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print "Content-type:text/html"
print
print "<html>"
print "<head>"
print "<meta charset=\"utf-8\">"
print "</head>"
print "<body>"
print "<h2>%s官网:%s</h2>" % (site_name, site_url)
print "</body>"
print "</html>"
文件保存后修改 hello_get.py,修改文件权限为 755:
chmod 755 hello_get.py
简单的表单实例:GET方法
以下是一个通过HTML的表单使用GET方法向服务器发送两个数据,提交的服务器脚本同样是hello_get.py文件,hello_get.html 代码如下:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> </head> <body> <form action="/cgi-bin/hello_get.py" method="get"> 站点名称: <input type="text" name="name"> <br /> 站点 URL: <input type="text" name="url" /> <input type="submit" value="提交" /> </form> </body> </html>
默认情况下 cgi-bin 目录只能存放脚本文件,我们将 hello_get.html 存储在 test 目录下,修改文件权限为 755:
使用POST方法传递数据
使用POST方法向服务器传递数据是更安全可靠的,像一些敏感信息如用户密码等需要使用POST传输数据。
以下同样是hello_get.py ,它也可以处理浏览器提交的POST表单数据:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print "Content-type:text/html"
print
print "<html>"
print "<head>"
print "<meta charset=\"utf-8\">"
print "</head>"
print "<body>"
print "<h2>%s官网:%s</h2>" % (site_name, site_url)
print "</body>"
print "</html>"
以下为表单通过POST方法(method=”post”)向服务器脚本 hello_get.py 提交数据:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> </head> <body> <form action="/cgi-bin/hello_get.py" method="post"> 站点名称: <input type="text" name="name"> <br /> 站点 URL: <input type="text" name="url" /> <input type="submit" value="提交" /> </form> </body> </html>